Home > Archives > 2010-12
2010-12
年末年始休業のお知らせ
- 2010-12-29 (水)
- 技術
皆様,今年も大変お世話になり誠にありがとうございました.
今年も残すところあと3日となりました.
思えばあっという間の2010年でした.
お客様をはじめ,私どもにご協力頂いた会社様,
お世話頂いた皆様にあらためて感謝申し上げます.
誠に恐縮ながら下記日時について休業いたしますので
どうぞご承知下さいますようお願い申し上げます.
2010年12月30日(木)~2011年1月4日(火)
1月5日(水)から通常通りの営業となっております.
来年もどうぞ皆様のご高配を賜りますよう宜しくお願い申し上げます.
アイエスエス株式会社社員一同
- Comments (Close): 0
- Trackbacks (Close): 0
OpenCVを使った機械学習
- 2010-12-27 (月)
- 技術
今日の話題は,OpenCVを使った機械学習.物体検出をご紹介しよう
ちなみに使ったOpenCVのバージョンは1.0.上位バージョンも大筋は変わらない.
機械学習に使うツールは、
・createsamples.exe
・haartraining.exe
なのだ.
これらはOpenCVをインストールすると、デフォルトで”C:\Program Files\OpenCV\bin”の下にできる.
1.学習データを用意する
学習に必要なデータは、学習対象の画像データ(正解画像)と、学習対象が写っていない不正解画像である。
正解画像7000、不正解画像3000位は必要と言われているらしい。
で、これらの画像から学習に使う、vecファイルなるものを作成するのだが、そこでcreatesamples.exeを使用する。
大量の正解画像を用意する方法は2つあり、まず根性で全部自分で用意する方法。そして回転等加え1つの画像から自動的に大量の画像を作成する方法である。
自力で画像を用意した場合、それらの情報を記述したファイルを用意する。
ファイルの書式は、
画像のパス 画像内の学習対象の数 学習対象領域の開始座標X Y 終了座標X Y
例えば以下の画像だと、
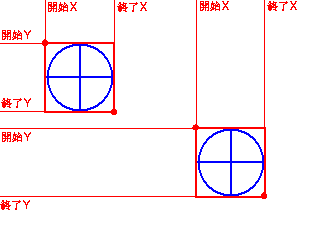
foloder/pogi_list_image.PNG 2 45 43 113 111 195 127 264 196
みたいな感じになる。
そんな感じですべての画像について記述したファイルを用意する。
さらに、不正解画像についてのリストファイルもつくる。こちらは仕様する全ての不正解画像のパスを記述する。
2.正解データのvecファイルを作成する
createsample.exeを使用してvecファイルを作成する。
createsamples.exe -info 正解画像リストファイル名 -vec 出力vecファイル名 -num 正解サンプル数 -w サンプル横幅 -h サンプル縦幅
最低限以上の引数があればよい。
例)createsample.exe -info positivelist.txt -vec positive.vec -num 1000 -w 24 -h 24
1つの画像から量産する場合は、画像ファイルを直接指定する。
例)createsample.exe -img positive.jpg -vec positive.vec -num 1000 -w 24 -h 24
他の引数は以下の通り
Usage: createsamples.exe
[-info (collection_file_name)]
[-img (image_file_name)]
[-vec (vec_file_name)]
[-bg (background_file_name)]:サンプル量産時の背景画像リストファイル(書式は不正解画像リストと同じ)
[-num (number_of_samples = 1000)]
[-bgcolor (background_color = 0)]
[-inv] [-randinv] [-bgthresh (background_color_threshold = 80)]
[-maxidev (max_intensity_deviation = 40)]
[-maxxangle (max_x_rotation_angle = 1.100000)]:サンプル量産時の回転範囲
[-maxyangle (max_y_rotation_angle = 1.100000)]:サンプル量産時の回転範囲
[-maxzangle (max_z_rotation_angle = 0.500000)]:サンプル量産時の回転範囲
[-show [(scale = 4.000000)]]
[-w (sample_width = 24)]:検出時の最小物体サイズになる
[-h (sample_height = 24)]:検出時の最小物体サイズになる
サンプル量産時は-bgを必ず指定したほうがいいと思う。
3.トレーニングを行う
OpenCvのbin内のhaartraining.exeを使用する。
haartraining.exe -data 出力検出器ファイル名 -vec 正解画像vecファイル名 -bg 不正解画像リストファイル名 -npos 正解サンプル数 -nneg 不正解サンプル数 -w サンプル横幅 -h サンプル縦幅
例)haartraining.exe -data out.xml -vec positive.vec -bg nagativelist.txt -npos 1000 -nneg 1000 -w 24 -h 24
他の引数は以下の通り
Usage: haartraining.exe
-data (dir_name)
-vec (vec_file_name)
-bg (background_file_name)
[-npos (number_of_positive_samples = 2000)]
[-nneg (number_of_negative_samples = 2000)]
[-nstages (number_of_stages = 14)]:多い方が精度が良いが、トレーニング時間が膨大になる
[-nsplits (number_of_splits = 1)]:多い方が精度が良いが、トレーニング時間が膨大になる
[-mem (memory_in_MB = 200)]:処理に使用可能な最大メモリ
[-sym (default)] [-nonsym]:正解画像が左右対称かどうか、非対称の場合-nonsymを指定するのだが、トレーニング時間が膨大になる
[-minhitrate (min_hit_rate = 0.995000)]
[-maxfalsealarm (max_false_alarm_rate = 0.500000)]
[-weighttrimming (weight_trimming = 0.950000)]
[-eqw]
[-mode (BASIC (default) | CORE | ALL)]
[-w (sample_width = 24)]
[-h (sample_height = 24)]
[-bt (DAB | RAB | LB | GAB (default))]
[-err (misclass (default) | gini | entropy)]
[-maxtreesplits (max_number_of_splits_in_tree_cascade = 0)]
[-minpos (min_number_of_positive_samples_per_cluster = 500)]
トレーニングが終了すると指定したファイル名のxmlファイルができる。
実験
今回は会社に何故か飾ってあるハム太郎のぬいぐるみを撮影し、学習、検出を行ってみることにした.
正解画像は1000、不正解画像は1020.
真正面から何枚か撮影し、それぞれ数百くらいずつのvecファイルを作り、複数のvecファイルを合成して1000のvecファイルを作成した。
不正解画像は,カルフォルニア工科大学様などが公開している画像データベースから拝借した様々な画像1020。
トレーニング時間は弊社のスーパーコンピュータで10時間くらい。
他のデータで試したときは3週間くらいかかっても終わらず、強制終了させたこともあった。
そして、結果発表.


 (目線は検出処理してから入れましたよ)
(目線は検出処理してから入れましたよ)
奨励画像数よりだいぶ少なかったが、結構がんばる。正面向き、回転少なめならばかなりの精度で検出する.
検出位置が微妙に右側にずれてるのが少し気になるところ.
今日ご紹介した方法で自分の好きな物体を検出できる.
ヤクルトの小瓶にひたすら反応する「ヤクルト検出器」や岩手県の形状に反応する「岩手県検出器」,あるいは馬の顔を検出する「馬顔検出」など応用は尽きないのである.
- Comments (Close): 0
- Trackbacks (Close): 0
Home > Archives > 2010-12
-

- Pages
- Recent Entries
- Links
-

- Categories
- Search
- Feeds
- Authorized
-

- Meta
 Copyright © 2002-2021 Innovative System Solutions Inc. All Rights Reserved.
Copyright © 2002-2021 Innovative System Solutions Inc. All Rights Reserved.